Scrapy-太原理工大学校园卡信息
最近啊因为疫情,每天在家双手寂寞难耐,不写点代码真的是太难受了。这段时间打算开发一个校园信息类的app,帮助大家免VPN查询成绩呀,课程呀,校园卡余额啦之类的。
我在上一篇博客已经介绍了我是如何对新的教务处接口动手动脚的,今天我又盯上了咱们的学生卡信息。一开始我也寻思这玩意好像除了去学校管理中心能查到其他地方也查不到呀,在学校的官网上一顿搜索我找到了这个学校官推app:校园网e卡通。这个app就可以查询到我们校园卡的详细信息,包括余额,账目信息。
本篇博客将详细的讲述我是如何拿到我想要的数据的,你需要对以下技术有所了解:
- Python基本语法
- Scrapy基本用法
- Http协议
- Django(可以不需要,但我的项目是Scrapy+Django整合,稍微说一点)
抓包分析
想要得到数据当然需要进行抓包,这里我选择fiddler4 + 夜神游戏模拟器。
fiddler4就不用我多说了吧,非常强大的抓包工具,夜神模拟器是一款用来在PC上模拟安卓手机的软件。因为我们要对手机app进行分析,配置手机直接连接fiddler经常会在Https请求上出问题,所以我选择在PC上装模拟器来进行抓包分析,话不多说下面开始正式的抓包!
fddler启动!夜神模拟器启动!bilibili启动!校园e卡通启动!
选择学校后会有登陆页面:
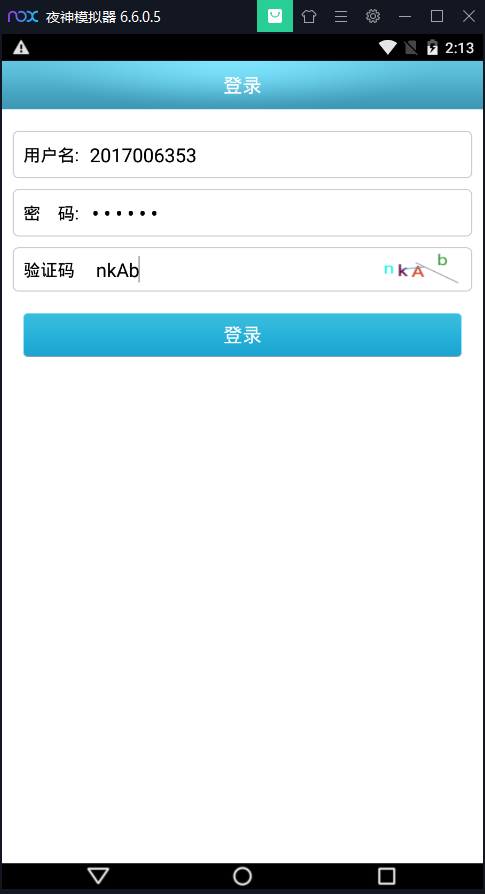
输入正确的信息登陆后查看fillder信息:

我们看到app向两个不同的IP地址发送了请求,但拿到数据的是http://202.207.245.234:9090/这个,这服务器也太垃圾了吧,连个端口都不省略,反向代理都没有。不管这些,我们在浏览器输入http://202.207.245.234:9090/先去看看情况:
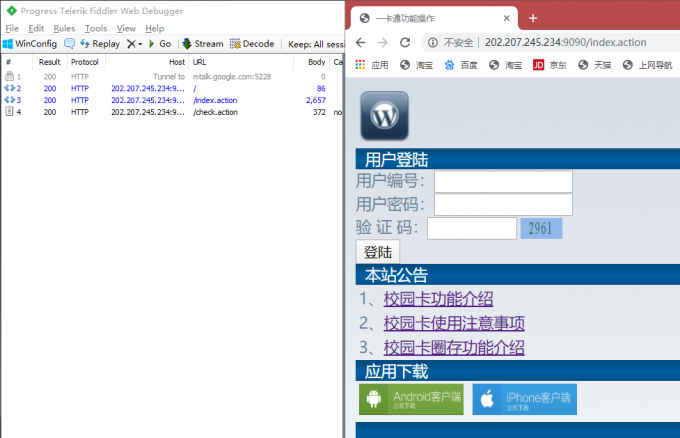
看到重定向到了index.action给我们返回了一个html,顺手还请求了check.action我猜这大概就是验证码图片的请求了,既然到了这一步那可以彻底和app说byebye了,接下来只需要浏览器和fillder就够了。登陆下看看fillder抓到的包:
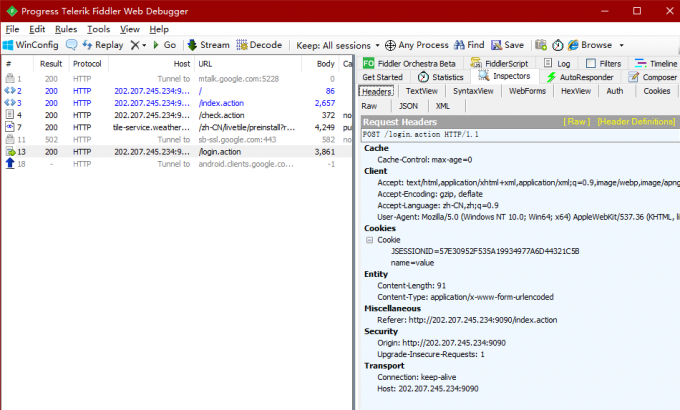
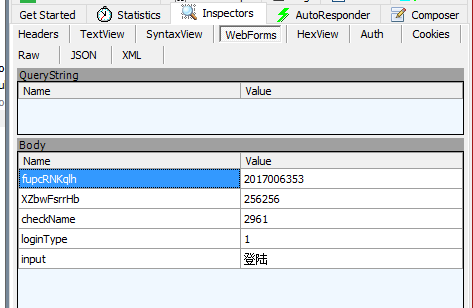
这种登陆查询一般都是用的cookie,所以这种Cookie信息一定要多留意,看了下请求的字段,这个用户名和密码的Name怎么这么奇怪?回到浏览器退出登陆回到登陆页面分析下HTML代码:
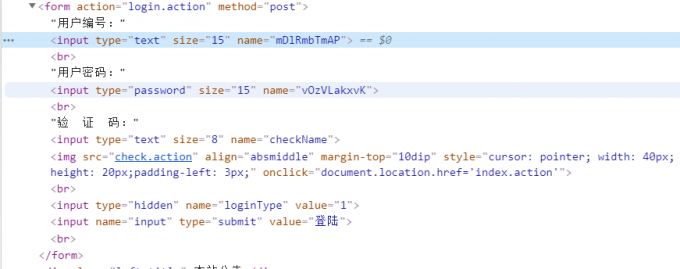
嗯哼?怎么和我刚才的请求Name不一样了?看来服务商还是有点东西的,我之后多次刷新发现每次的Name都不一样,在接下来的爬虫需要注意这一点了。
包也抓了,网页也分析了,该写Spider了,接下来我将说明如何写好爬虫,这才是重中之重!
Spider编写
我先来写一个拿到余额的Spider,其中主要有以下几个要点:
- 设置指定pipline,因为我要存到数据库所以需要指定的pipline来清洗,保存数据
- 初始化传入username和password
- 使用Item存储数据
- 刚才的请求Name每次浏览都会变化,我需要通过xpath来拿到字段,构造请求字段
- 在获取验证码的时候我用原生的urllib库去得到验证码图片
- 识别验证码选择百度的通用文字识别,每天 免费5w次,足够用了
- 百度API识别图片需要base64或者url,所以我们需要把刚才拿到的图片转base64编码,传给我调用的yzm函数,他会返回给我验证码的结果
class AmountSpider(Spider):
name = "amount"
# 指定pipline
custom_settings = {
'ITEM_PIPELINES': {
'eduScrapy.pipelines.amountPipline': 300
}
}
def __init__(self, username=None, password=None, *args, **kwargs):
super(AmountSpider, self).__init__(*args, **kwargs)
self.username = username
self.password = password
def start_requests(self):
url = "http://202.207.245.234:9090/"
yield Request(url, self.getcheck)
def getcheck(self, response):
url = "http://202.207.245.234:9090/login.action"
Cookie = response.request.headers.getlist('Cookie')
cookies = {}
for cookie in Cookie:
# 转码并对每一行用 = 分隔开,在加入到字典当中
cookie = cookie.decode("utf-8").split('=')
cookies[cookie[0]] = cookie[1]
# 获取登录表单字段
username = response.xpath('/html/body/form/input[1]/@name').get()
password = response.xpath('/html/body/form/input[2]/@name').get()
# 获取验证码,并识别
headers = {'Cookie': Cookie[0].decode("utf-8"),
"Connection": "keep-alive",
"Referer": "http://202.207.245.234:9090/index.action"}
request = urllib.request.Request("http://202.207.245.234:9090/check.action", headers=headers, method="GET")
response = urllib.request.urlopen(request)
checkname = yzm(response.read())["words_result"][0]["words"]
# post数据
formatdata = {
username: self.username,
password: self.password,
"checkName": checkname,
"loginType": '1',
"input": "登陆"
}
yield FormRequest(url=url, cookies=cookies, callback=self.getBalance, method="POST", formdata=formatdata)
def getBalance(self, response):
url = "http://202.207.245.234:9090/queryBalance.action"
Cookie = response.request.headers.getlist('Cookie')
cookies = {}
for cookie in Cookie:
# 转码并对每一行用 = 分隔开,在加入到字典当中
cookie = cookie.decode("utf-8").split('=')
cookies[cookie[0]] = cookie[1]
yield FormRequest(url=url, cookies=cookies, callback=self.parse, method="GET")
def parse(self, response):
Item = amountItem()
Item['amount'] = response.xpath('/html/body/table//td/font/text()').get()
Item['studentid'] = self.username
yield Item
run一下看一下结果吧:

我想要账户明细的数据怎么做呢?还是先去抓包分析一下吧:
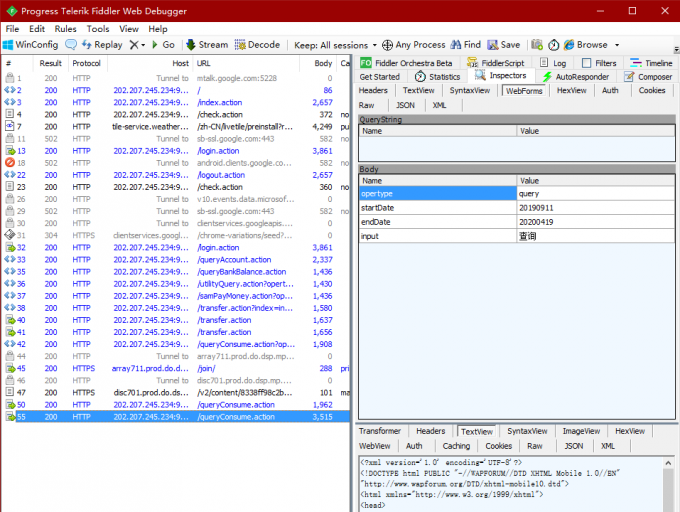
看到请求字段我就明白了,查询给出起始日期和结束日期就可以进行查询了,返回的页面并不是一次性给出所有的明细,而是做了分页,我们想要所有的数据当然需要点击下一页再看看是如何请求数据的:
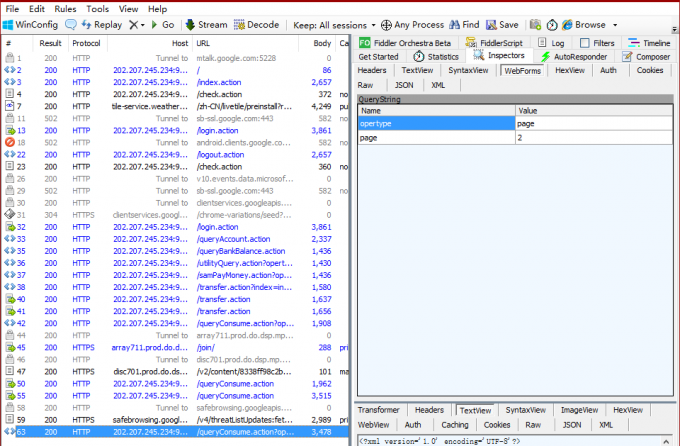
这次是GET请求,请求字段也很简单,只有opertype和page很好理解,接下来就继续编写我们的Spider,其中有以下几个要点:
- 该Spider与查询余额的Spider并没有很大的区别,一法通,万法通
-
初始化除了username和password以外还需要startDate和endDate,表明查询的开始
- 对于分页需要先拿到页数,直接用Xpath去拿到尾页按钮里面的页数
- 数据以日期,部门,金额来保存
class CustomeSpider(Spider):
name = "custome"
# 指定pipline
custom_settings = {
'ITEM_PIPELINES': {
'eduScrapy.pipelines.consumePipline': 300
}
}
def __init__(self, username=None, password=None, startDate=datetime.today().strftime('%Y%m%d'),
endDate=datetime.today().strftime('%Y%m%d'), *args, **kwargs):
super(CustomeSpider, self).__init__(*args, **kwargs)
self.endDate = endDate
self.startDate = startDate
self.username = username
self.password = password
def start_requests(self):
url = "http://202.207.245.234:9090/"
yield Request(url, self.getcheck)
def getcheck(self, response):
url = "http://202.207.245.234:9090/login.action"
Cookie = response.request.headers.getlist('Cookie')
cookies = {}
for cookie in Cookie:
# 转码并对每一行用 = 分隔开,在加入到字典当中
cookie = cookie.decode("utf-8").split('=')
cookies[cookie[0]] = cookie[1]
# 获取登录表单字段
username = response.xpath('/html/body/form/input[1]/@name').get()
password = response.xpath('/html/body/form/input[2]/@name').get()
# 获取验证码,并识别
headers = {'Cookie': Cookie[0].decode("utf-8"),
"Connection": "keep-alive",
"Referer": "http://202.207.245.234:9090/index.action"}
request = urllib.request.Request("http://202.207.245.234:9090/check.action", headers=headers, method="GET")
response = urllib.request.urlopen(request)
checkname = yzm(response.read())["words_result"][0]["words"]
# post数据
formatdata = {
username: self.username,
password: self.password,
"checkName": checkname,
"loginType": '1',
"input": "登陆"
}
yield FormRequest(url=url, cookies=cookies, callback=self.getCustome, method="POST", formdata=formatdata)
def getCustome(self, response):
url = "http://202.207.245.234:9090/queryConsume.action"
Cookie = response.request.headers.getlist('Cookie')
cookies = {}
for cookie in Cookie:
# 转码并对每一行用 = 分隔开,在加入到字典当中
cookie = cookie.decode("utf-8").split('=')
cookies[cookie[0]] = cookie[1]
# post数据
formatdata = {
"opertype": "query",
"startDate": self.startDate,
"endDate": self.endDate,
"input": "查询"
}
yield FormRequest(url=url, cookies=cookies, callback=self.Customepage, method="POST", formdata=formatdata)
def Customepage(self, response):
Cookie = response.request.headers.getlist('Cookie')
cookies = {}
for cookie in Cookie:
# 转码并对每一行用 = 分隔开,在加入到字典当中
cookie = cookie.decode("utf-8").split('=')
cookies[cookie[0]] = cookie[1]
# 拿到最后一页的页码
endpage = int(re.findall(r"\d+\.?\d*", response.xpath('/html/body/a[4]/@href').get())[0])
# 拿到分页数据
for i in range(1, endpage + 1):
url = "http://202.207.245.234:9090/queryConsume.action?opertype=page&page="
yield FormRequest(url=url + str(i), cookies=cookies, callback=self.parse, method="GET")
def parse(self, response):
item = customeItem()
for i in range(2, 11):
item['date'] = response.xpath('/html/body/table/tr[' + str(i) + ']/td[1]/text()').get()
item['department'] = response.xpath('/html/body/table/tr[' + str(i) + ']/td[2]/text()').get()
item['amount'] = response.xpath('/html/body/table/tr[' + str(i) + ']/td[3]/text()').get()
yield item
pass
run一下看一下结果:
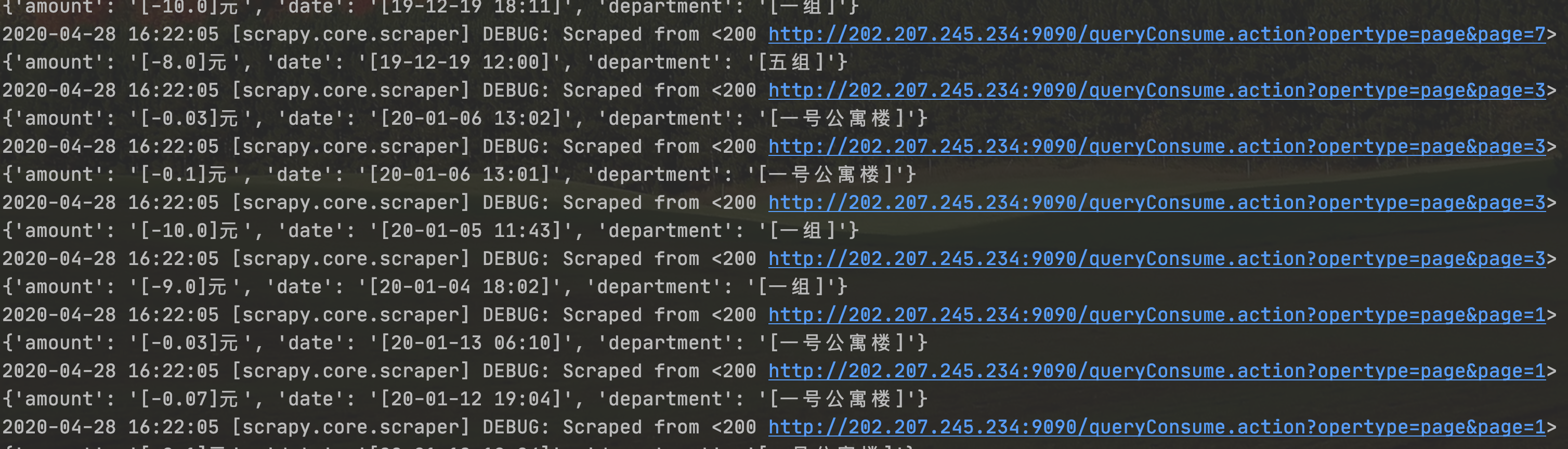
总结
很多人和我说在学习爬虫的过程中很吃力,文档看不懂,照着书上的样例来写经常出错,或者网页已经有了很大变化,自己动手编写爬虫无从下手,我有一些经验和大家分享:
- 我觉得对于初学者一定要对HTTP协议有着较为清晰的认识,如果你都不知道POST与GET请求的区别,就算照猫画虎写出了爬虫,实战的时候还是会手足无措。你需要了解Request和Respones的信息,还有一些web应用的技术例如Cookie,token,session这些。
- 其次,html简单的东西你总得了解吧,你都不知道什么是html/CSS/JS,那爬虫对你来说还是有点早了。一些新的技术你也得有涉猎,比如Ajax这样的异步请求方式,这样才能在写爬虫的时候对症下药。
- 学习一些爬虫框架能够大大提升工作效率,比如Scrapy这样的。
如果你想要了解我的校园网项目,或者了解Scrapy编写的详细内容请关注我在github上的开源项目:https://github.com/snake-lvyonghao/Tyut-Proxy。
好了,希望这篇博文对你有用,我是Snake,祝你幸福!