Scrapy-太原理工大学教务处
在这之前我写过一篇关于用Java语言来实现的爬虫,但因为教务处的后台进行了升级,之前的接口没有办法再使用了,我也知道好多太理的学子日常是不喜欢挂vpn然后再用网页的形式去访问教务处,大家都通过了微信公众号或者微信小程序,app来查询成绩,看看课表。所以我打算对新的接口用Scrapy去爬数据,接下来我和大家分享下我在编写爬虫时遇到的坑,还有解决方案,无论是你想要来学习模拟登陆的操作,还是想要取取经也想自己折腾,我保证不让你失望。
你需要有以下知识基础:
- Python语言基础
- 了解Scrapy是什么
- web前端
- 服务器的请求方式,以及Ajax异步请求
本篇博客会很长,需要有耐心,我会从头到尾仔细的分析并解决问题,谢谢
分析网页
分析网页我选择使用Chrome和Fildder来抓包,为了方便学习,我这里用chrome浏览器来演示,打开登陆界面浏览器内ctrl + F12打开调试页面:
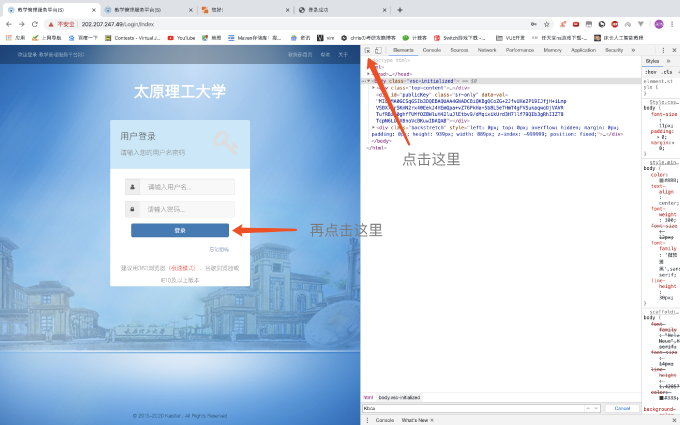
点击小箭头你再到页面上点击跳转到你你点击位置的网页源代码,这里我们检查登陆
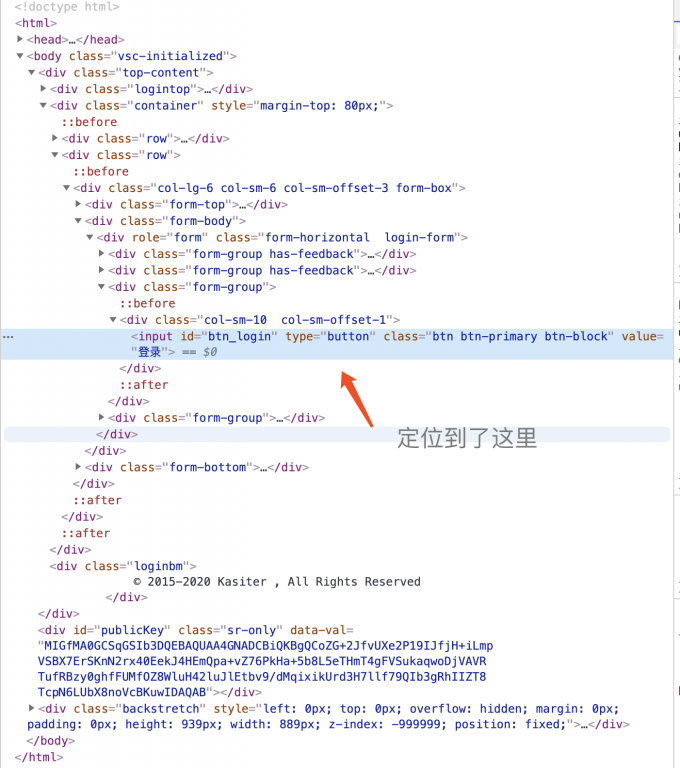
发现他不是我们想象中的form,也就没法看到他请求的地址了,遇到这样的情况可以试着去搜索下这个input标签的id,一般都是javascrip事件来实现的,我们在这里ctrl + F 搜索btn_login

看到在script中大量使用了$(),这样的是使用了JQuery,我们能看到他对username,password,verifycode变量赋值,重要的是左后==最后调用了CheckLogin这个函数,这个函数就在下方,我们分析这个方法,其中里面有着很重要的部分
var publickey = $('#publicKey').data("val");
var crypt = new JSEncrypt();
crypt.setPublicKey(publickey);
//lxd 2018-11-02 加密账号,用来登录教学管理平台
var encryptedUsername = crypt.encrypt(username);
encryptedUsername = encodeURI(encryptedUsername).replace(/\+/g, '%2B');
定义了一个新的变量publickey,从Id为publicKey中拿到属性data-val的值,在元素检查查找这个id我们会找到公钥
<div id="publicKey" class="sr-only" data-val="MIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQCoZG+2JfvUXe2P19IJfjH+iLmp
VSBX7ErSKnN2rx40EekJ4HEmQpa+vZ76PkHa+5b8L5eTHmT4gFVSukaqwoDjVAVR
TufRBzy0ghfFUMfOZ8WluH42luJlEtbv9/dMqixikUrd3H7llf79QIb3gRhIIZT8
TcpN6LUbX8noVcBKuwIDAQAB">
</div>
后面大家也能看出来把公钥放进去,然后对username进行加密,处理字符串把加号转码,好的加密完了就用ajax来传输数据了,我们看到如下的代码
$.ajax({
type: "post",
url: "$.ajax({
type: "post",
url: "/Login/CheckLogin",
data: { username: encryptedUsername, password: password, code: verifycode, isautologin: autologin },
cache: false,
dataType: "json",
beforeSend: function () {
$("#btn_login").attr("disabled", "disabled");
},
success: function (data) {
if (data.type === 1) {
window.location.href = '/Home/Default';
} else {
dialogAlert(data.message, 0);
}
},
complete: function () {
$("#btn_login").removeAttr("disabled");
},
error: function (xmlHttpRequest, textStatus, errorThrown) {
//alert("系统错误 status:" + xmlHttpRequest.status + " readyState:" + xmlHttpRequest.readyState + ",请稍后重试或于管理员联系!");
dialogAlert(xmlHttpRequest.responseText, -1);
}",
data: { username: encryptedUsername, password: password, code: verifycode, isautologin: autologin },
cache: false,
dataType: "json",
beforeSend: function () {
$("#btn_login").attr("disabled", "disabled");
},
success: function (data) {
if (data.type === 1) {
window.location.href = '/Home/Default';
} else {
dialogAlert(data.message, 0);
}
},
complete: function () {
$("#btn_login").removeAttr("disabled");
},
error: function (xmlHttpRequest, textStatus, errorThrown) {
//alert("系统错误 status:" + xmlHttpRequest.status + " readyState:" + xmlHttpRequest.readyState + ",请稍后重试或于管理员联系!");
dialogAlert(xmlHttpRequest.responseText, -1);
}
在这里我们终于找到请求的地址/Login/CheckLogin,post提交方式,参数有username,password,code,isautologin,这里的username已经是加密过后的,使用json格式传输数据。再看下面的回调函数,做了一个简单的判断type属性==1就跳转请求/Home/Default。好的到此为止我们对网页的分析就结束了,我们先登陆一下看一下他实际的请求再进行分析,输入账号,密码,使用chrome自带的NetWork来看我们发送的请求:
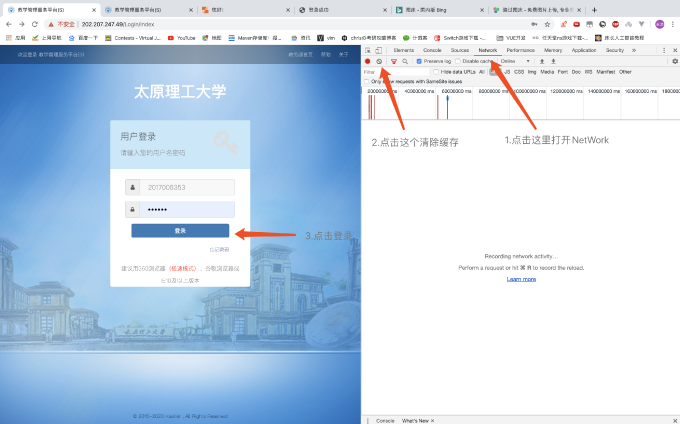
登陆后我们会看到各种各样的文件,因为我们已经知道他是使用ajax发起异步请求,所以我们只看XHR下的文件就可以了,第一个就是一个名为CheckLogin的文件,在里面我们可以看到请求头,以及提交的参数
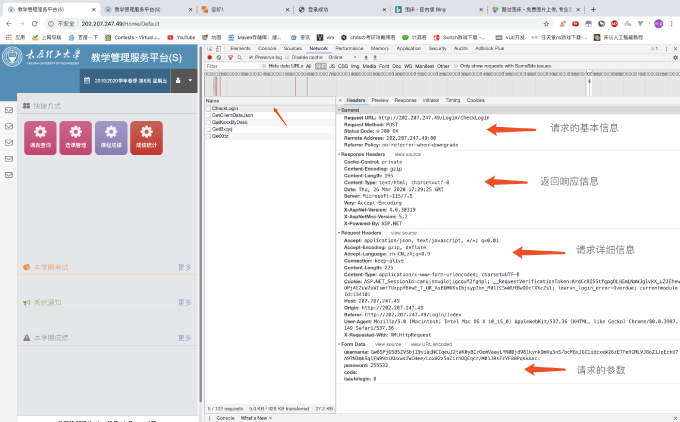
相应的信息看图就好,基本信息得出没有使用referrer防盗链技术,请求的详细信息中有X-Requested-With:
XMLHttpRequest,和Cookie,这在我们构造请求的时候这些内容都得加上。整个流程就是登陆判断返回信息,信息正确就跳转到首页,在这里我就能确定一定是使用cookie来实现的,所以我们还需要拿到登陆后的Cookie。在前面我们还有一个很大的问题没有解决,就是加密的用户名怎么构造,知道了这些问题后我们来逐个解决。
具体解决问题以及模拟登陆获取课表
我在网上查阅资料后知道了他的加密方式是RSA加密,在这里我不打算详细的去介绍这套加密算法,使用PyCrypto这个模块通过publickey来构造一个加密后的username,因为我使用的是Scrapy,所以我在项目内写了这样一个工具类,用来获取加密后的username
# publickey算法
import base64
from Crypto.Cipher import PKCS1_v1_5 as Cipher_pkcs1_v1_5
from Crypto.PublicKey import RSA
def crack_pwd(key, pwd):
key = "-----BEGIN PUBLIC KEY-----\n" + key + "\n-----END PUBLIC KEY-----"
rsakey = RSA.importKey(key)
cipher = Cipher_pkcs1_v1_5.new(rsakey) # 生成对象
cipher_text = base64.b64encode(cipher.encrypt(pwd.encode(encoding="utf-8"))) # 对传递进来的用户名或密码字符串加密
value = cipher_text.decode('utf8') # 将加密获取到的bytes类型密文解码成str类型
return value
传入参数公钥和你要加密的字段,返回加密后的字符串,这个应该很好理解,接下来我们编写实际的Spider模拟登陆并查询课程表信息,新建一个Spider这个操作应该不过分吧!我就不说了。
模拟登陆分为这几步:
- 首先向首页发起请求
- 通过Xpath来获取公钥的内容,这一步可以在Chrome元素检查中对应内容右键就有CopyXpath的选项
- 设置请求的参数
- 设置请求头,直接从Chrome中的Request Headers中复制就好,重点是’X-Requested-With’: ‘XMLHttpRequest’,如果请求头不加这一段服务器会直接302,也就是重定向到一个该页面不存在的网页
到了getCookie其实就已经登陆成功了我去判断了一下返回信息的type,因为也有可能账号密码错误的,怎么处理错误信息我还没想好所以就先pass了。登陆后我们想要班级课表的数据,那就再用chrome的network工具去分析一下他请求的地址,以及相应的信息,设置相应的信息。
- 我是如何获取Cookie的呢?通过response.request.headers,其实你请求的所有信息都包含在里面,怎么提取就直接看代码吧,很简单的操作
- 通过拿到的Cookie去访问课表数据的链接就可以得到相应的数据,不过这里还有一个小坑,就是Scrapy默认不使用Cookie,如果想要自定义Cookie就需要在seting.py中打开Cookie设置
# Disable cookies (enabled by default)
COOKIES_ENABLED = True
- 在最后我希望拿到json格式的数据,所以做了一下简单的处理,因为格式的问题不能显示相应的中文,转了utf-8格式就没有问题了
import json
import base64
import scrapy
from Crypto.PublicKey import RSA
from Crypto.Cipher import PKCS1_v1_5 as Cipher_pkcs1_v1_5
from scrapy import Spider, Request, cmdline, FormRequest
from scrapy.http import Request, FormRequest
from eduScrapytest import Tool
class jwxt(Spider):
name = "jwxt"
# 首先拿到RSA的publickey
def start_requests(self):
# 设置请求校园网网址
url = "http://202.207.247.49"
yield Request(url, self.login_parse)
def login_parse(self, response):
publickey = response.xpath("/html/body/div[2]/@data-val").extract()[0]
url = "http://202.207.247.49/Login/CheckLogin"
# username = self.crack_pwd(publickey, '2017006353')
username = Tool.crack_pwd(publickey, '2017006353')
formatdata = {
'username': username,
'password': '255532',
'code': '',
'isautologin': '0'
}
cookies = {}
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Host': '202.207.247.49',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Referer': 'http://202.207.247.49/Login/Index',
'Origin': 'http://202.207.247.49/',
'Connection': 'keep-alive',
}
# yield Request(url=url,callback=self.parse,method="POST",body=json.dumps(formatdata),headers=headers)
yield FormRequest(url=url, cookies=cookies, formdata=formatdata, callback=self.getCookie,
method="POST", headers=headers)
# 登陆成功后获取Cookie
def getCookie(self, response):
message = response.text.replace("null", "0")
message = eval(message)
if message["type"] == 1:
url = "http://202.207.247.49/Home/Default"
# 获取登陆请求的Cookie
Cookie = response.request.headers.getlist('Cookie')
cookies = {}
# 便利整个cookies
for cookie in Cookie:
# 转码并对每一行用 = 分隔开,在加入到字典当中
cookie = cookie.decode("utf-8").split('=')
cookies[cookie[0]] = cookie[1]
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Host': '202.207.247.49',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Referer': 'http://202.207.247.49/Login/Index',
'Origin': 'http://202.207.247.49',
'Connection': 'keep-alive',
}
yield FormRequest(url=url, cookies=cookies, callback=self.GeXsKb, method="POST", headers=headers)
else:
# 登陆失败相应处理
pass
# 获取班级课表
def GeXsKb(self, response):
url = "http://202.207.247.49/Tresources/A1Xskb/GetXsKb"
Cookie = response.request.headers.getlist('Cookie')
cookies = {}
formdata = {
'zxjxjhh':''
}
# 遍历整个cookies
for cookie in Cookie:
# 转码并对每一行用 = 分隔开,在加入到字典当中
cookie = cookie.decode("utf-8").split('=')
cookies[cookie[0]] = cookie[1]
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Host': '202.207.247.49',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Referer': 'http://202.207.247.49/Tresources/A1Xskb/XsKbIndex',
'Origin': 'http://202.207.247.49',
'Connection': 'keep-alive',
}
yield FormRequest(url=url, cookies=cookies, callback=self.parse, method="POST", headers=headers,formdata=formdata)
def parse(self, response):
message = eval(response.text.replace("null", "0"))
message = json.dumps(message, ensure_ascii=False)
print(message)
if __name__ == '__main__':
cmdline.execute("scrapy crawl jwxt".split())
运行后我们可以得到相应的课程数据,我拿出来放到json格式的文件中保存,就是这个样子的:
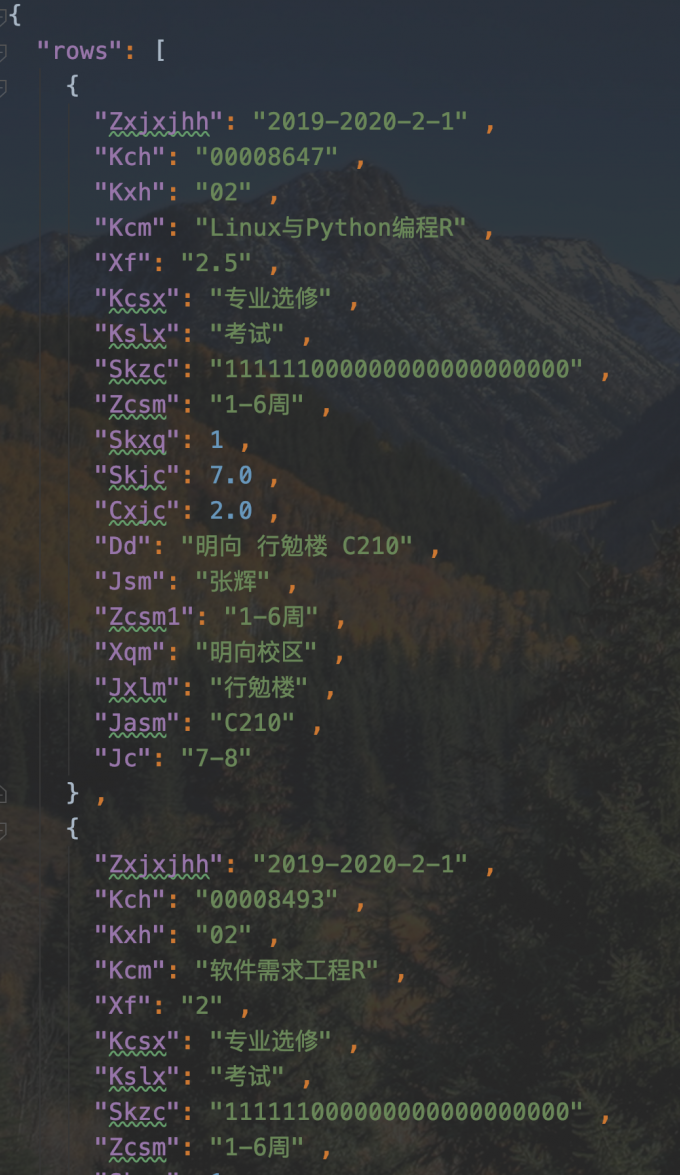
爬取成绩统计信息以及课程成绩信息并使用ITem封装数据
使用Scrapy我们都知道为了能够返回字典格式的数据我们通常会使用ITem帮助我们封装爬取的数据,接下来就看看是怎样实现的把,因为和前面爬取课程表信息有很多相似的地方所以我不会特别详细的再去讲述了,只说一些关键的数据处理。
在Item.py中 先定义成绩统计信息和课程成绩信息的Item
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class EduscrapytestItem(scrapy.Item):
ClassId = scrapy.Field() # 学号
Class = scrapy.Field() # 班级
Coct = scrapy.Field() # 已修课程学分
Gpa = scrapy.Field() # GPA
GpaSort = scrapy.Field() # GPA专业排名
WeightSort = scrapy.Field() # 加权班级排名
AverageCredit = scrapy.Field() # 平均成绩
AverageCreditSort = scrapy.Field() # 平均成绩专业排名
FailingCredits = scrapy.Field() # 尚不及格学分
Name = scrapy.Field() # 姓名
TotalCreditsRequired = scrapy.Field() # 要求总学分
ComInPraCre = scrapy.Field() # 已修自主实践学分
GpaSortClass = scrapy.Field() # GPA班级排名
WeightCredit = scrapy.Field() # 加权学分成绩
WeightCreditSort = scrapy.Field() # 加权专业排名
AverageSortClass = scrapy.Field() # 平均成绩班级排名
FailedCredits = scrapy.Field() # 曾不及格学分
class KccjItem(scrapy.Item):
ClassId = scrapy.Field()
ClassName = scrapy.Field()
GPA = scrapy.Field()
ClassAttribute = scrapy.Field()
TestTime = scrapy.Field()
Credit = scrapy.Field()
通过NetWork发现无论是课程表,还是成绩统计,课程成绩,都是ajax返回相应的数据,这样处理起来就很轻松,只要访问相应的地址,服务器就给我们返回的信息中就有我们要的内容。成绩统计没什么好说的把数据拿到放到ITem就好了,我直接贴代码
from scrapy import Spider, Request, FormRequest, cmdline
from eduScrapytest.items import EduscrapytestItem
from eduScrapytest import Tool
class xskkc(Spider):
name = "xskkc"
# 首先拿到RSA的publickey
def start_requests(self):
# 设置请求校园网网址
url = "http://202.207.247.49"
yield Request(url, self.login_parse)
def login_parse(self, response):
publickey = response.xpath("/html/body/div[2]/@data-val").extract()[0]
url = "http://202.207.247.49/Login/CheckLogin"
username = Tool.crack_pwd(publickey, '2017006353')
formatdata = {
'username': username,
'password': '255532',
'code': '',
'isautologin': '0'
}
cookies = {
# "ASP.NET_SessionId":"canujsnuqlojigcquf2fg4pl",
# '__RequestVerificationToken':'KrdCc8ISStfgpgOLHEmLNaWJglvkX_uZJEhewOPjAEZuW2uWIsmtTUzppfBVwE_T_UK_AsB6M6KsIbjsypIbn_M0lIC5wWUfBwDOcTXXcZs1',
# 'learun_login_error':'Overdue',
}
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Host': '202.207.247.49',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Referer': 'http://202.207.247.49/Login/Index',
'Origin': 'http://202.207.247.49/',
'Connection': 'keep-alive',
}
# yield Request(url=url,callback=self.parse,method="POST",body=json.dumps(formatdata),headers=headers)
yield FormRequest(url=url, cookies=cookies, formdata=formatdata, callback=self.getCookie,
method="POST", headers=headers)
# 登陆成功后获取Cookie
def getCookie(self, response):
message = response.text.replace("null", "0")
message = eval(message)
if message["type"] == 1:
url = "http://202.207.247.49/Home/Default"
# 获取登陆请求的Cookie
Cookie = response.request.headers.getlist('Cookie')
cookies = {}
# 便利整个cookies
for cookie in Cookie:
# 转码并对每一行用 = 分隔开,在加入到字典当中
cookie = cookie.decode('utf-8').split('=')
cookies[cookie[0]] = cookie[1]
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Host': '202.207.247.49',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Referer': 'http://202.207.247.49/Login/Index',
'Origin': 'http://202.207.247.49',
'Connection': 'keep-alive',
}
yield FormRequest(url=url, cookies=cookies, callback=self.GeXsKb, method="GET", headers=headers)
else:
# 登陆失败相应处理
pass
# 获取成绩统计分析
def GeXsKb(self, response):
url = 'http://202.207.247.49/Tschedule/C6Cjgl/GetXskccjResult'
Cookie = response.request.headers.getlist('Cookie')
cookies = {}
# 便利整个cookies
for cookie in Cookie:
# 转码并对每一行用 = 分隔开,在加入到字典当中
cookie = cookie.decode("utf-8").split('=')
cookies[cookie[0]] = cookie[1]
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Host': '202.207.247.49',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Referer': 'http://202.207.247.49/Tschedule/C6Cjgl/XskccjIndex',
'Origin': 'http://202.207.247.49',
'Connection': 'keep-alive',
}
yield FormRequest(url=url, cookies=cookies, callback=self.parse, method="POST",
headers=headers)
def parse(self, response):
item = EduscrapytestItem()
item['ClassId'] = response.xpath('/html/body/div[1]/div/div[1]/div[2]/span/text()').extract()[0]
item['Class'] = response.xpath('/html/body/div[1]/div/div[2]/div[2]/span/text()').extract()[0]
item['Coct'] = response.xpath('/html/body/div[1]/div/div[3]/div[2]/span/text()').extract()[0]
item['Gpa'] = response.xpath('/html/body/div[1]/div/div[4]/div[2]/span/text()').extract()[0]
item['GpaSort'] = response.xpath('/html/body/div[1]/div/div[5]/div[2]/span/text()').extract()[0]
item['WeightSort'] = response.xpath('/html/body/div[1]/div/div[6]/div[2]/span/text()').extract()[0]
item['WeightSort'] = response.xpath('/html/body/div[1]/div/div[7]/div[2]/span/text()').extract()[0]
item['AverageCreditSort'] = response.xpath('/html/body/div[1]/div/div[8]/div[2]/span/text()').extract()[0]
item['FailingCredits'] = response.xpath('/html/body/div[1]/div/div[9]/div[2]/span/text()').extract()[0]
item['Name'] = response.xpath('/html/body/div[2]/div/div[1]/div[2]/span/text()').extract()[0]
item['TotalCreditsRequired'] = response.xpath('/html/body/div[2]/div/div[2]/div[2]/span/text()').extract()[0]
item['ComInPraCre'] = response.xpath('/html/body/div[2]/div/div[3]/div[2]/span/text()').extract()[0]
item['GpaSortClass'] = response.xpath('/html/body/div[2]/div/div[4]/div[2]/span/text()').extract()[0]
item['WeightCredit'] = response.xpath('/html/body/div[2]/div/div[5]/div[2]/span/text()').extract()[0]
item['WeightCreditSort'] = response.xpath('/html/body/div[2]/div/div[6]/div[2]/span/text()').extract()[0]
item['AverageSortClass'] = response.xpath('/html/body/div[2]/div/div[7]/div[2]/span/text()').extract()[0]
item['FailedCredits'] = response.xpath('/html/body/div[2]/div/div[8]/div[2]/span/text()').extract()[0]
print(item)
if __name__ == '__main__':
cmdline.execute("scrapy crawl xskkc".split())
运行后可以看到个人成绩统计的详细信息,请忽略掉我那不堪入目的成绩:
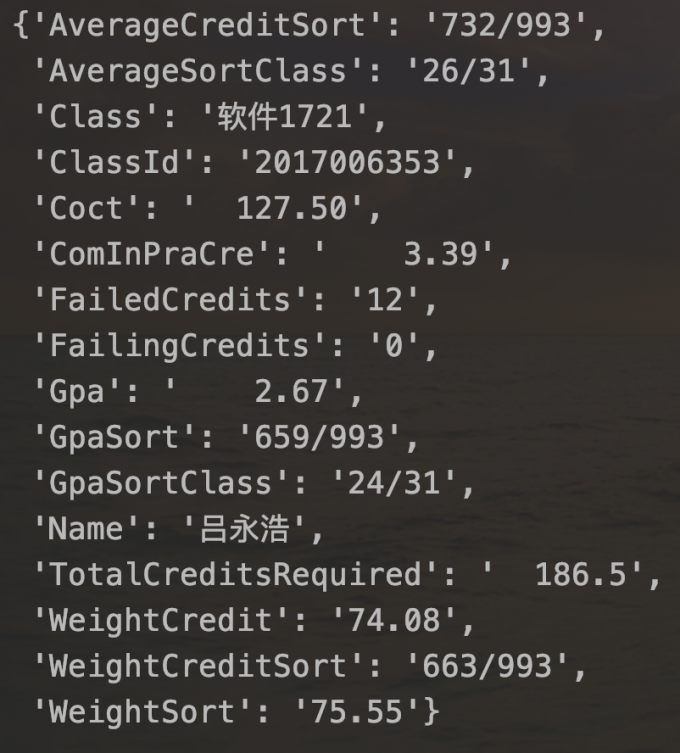
这里能看出来输出item就是字典的形式,这就很方便我们后续的操作了。
对于课程成绩我们拿到的服务器的返回值是这样子的:
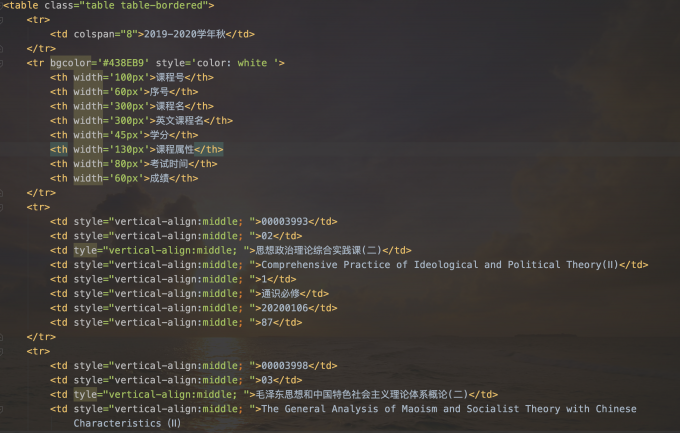
观察数据我发现每一个<tr>中包含了每门课的信息,但也有的<tr>里面不是我们想要的数据,我们需要过滤掉,并且考虑到每个人的课程数量不一样,所以我的方案是先拿到所有的tr,迭代selectorList,再用生成器来生成每一个课程的信息,使用两层Xpath来提取数据,具体请见代码:
from scrapy import Spider, Request, FormRequest, cmdline
from eduScrapytest.items import KccjItem
from eduScrapytest import Tool
class kccj(Spider):
name = "kccj"
# 首先拿到RSA的publickey
def start_requests(self):
# 设置请求校园网网址
url = "http://202.207.247.49"
yield Request(url, self.login_parse)
def login_parse(self, response):
publickey = response.xpath("/html/body/div[2]/@data-val").extract()[0]
url = "http://202.207.247.49/Login/CheckLogin"
username = Tool.crack_pwd(publickey, '2017006353')
formatdata = {
'username': username,
'password': '255532',
'code': '',
'isautologin': '0'
}
cookies = {
# "ASP.NET_SessionId":"canujsnuqlojigcquf2fg4pl",
# '__RequestVerificationToken':'KrdCc8ISStfgpgOLHEmLNaWJglvkX_uZJEhewOPjAEZuW2uWIsmtTUzppfBVwE_T_UK_AsB6M6KsIbjsypIbn_M0lIC5wWUfBwDOcTXXcZs1',
# 'learun_login_error':'Overdue',
}
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Host': '202.207.247.49',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Referer': 'http://202.207.247.49/Login/Index',
'Origin': 'http://202.207.247.49/',
'Connection': 'keep-alive',
}
# yield Request(url=url,callback=self.parse,method="POST",body=json.dumps(formatdata),headers=headers)
yield FormRequest(url=url, cookies=cookies, formdata=formatdata, callback=self.getCookie,
method="POST", headers=headers)
# 登陆成功后获取Cookie
def getCookie(self, response):
message = response.text.replace("null", "0")
message = eval(message)
if message["type"] == 1:
url = "http://202.207.247.49/Home/Default"
# 获取登陆请求的Cookie
Cookie = response.request.headers.getlist('Cookie')
cookies = {}
# 便利整个cookies
for cookie in Cookie:
# 转码并对每一行用 = 分隔开,在加入到字典当中
cookie = cookie.decode('utf-8').split('=')
cookies[cookie[0]] = cookie[1]
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Host': '202.207.247.49',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Referer': 'http://202.207.247.49/Login/Index',
'Origin': 'http://202.207.247.49',
'Connection': 'keep-alive',
}
yield FormRequest(url=url, cookies=cookies, callback=self.getkkcj, method="GET", headers=headers)
else:
# 登陆失败相应处理
pass
def getkkcj(self,response):
url = 'http://202.207.247.49/Tschedule/C6Cjgl/GetKccjResult'
Cookie = response.request.headers.getlist('Cookie')
cookies = {}
# 便利整个cookies
for cookie in Cookie:
# 转码并对每一行用 = 分隔开,在加入到字典当中
cookie = cookie.decode("utf-8").split('=')
cookies[cookie[0]] = cookie[1]
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Host': '202.207.247.49',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Referer': 'http://202.207.247.49/Tschedule/C6Cjgl/KccjIndex',
'Origin': 'http://202.207.247.49',
'Connection': 'keep-alive',
}
formdata = {
'order':'zxjxjhh desc,kch'
}
yield FormRequest(url=url, cookies=cookies, callback=self.parse, method="POST",formdata=formdata,
headers=headers)
def parse(self, response):
kccjResultList = []
tr = response.xpath('//tr')
for td in tr:
Item = KccjItem()
if td.xpath('td[1][not(@colspan)]/text()').get() == None:
continue
Item['ClassId'] = td.xpath('td[1][not(@colspan)]/text()').get()
Item['ClassName'] = td.xpath('td[3]/text()').get()
Item['GPA'] = td.xpath('td[5]/text()').get()
Item['ClassAttribute'] = td.xpath('td[6]/text()').get()
Item['TestTime'] = td.xpath('td[7]/text()').get()
Item['Credit'] = td.xpath('td[8]/text()').get()
yield print(Item)
if __name__ == '__main__':
cmdline.execute("scrapy crawl kccj".split())
运行后可以看到yield生成了每一门课程的具体信息,因为有的信息不需要所有我没有封装到ITem里
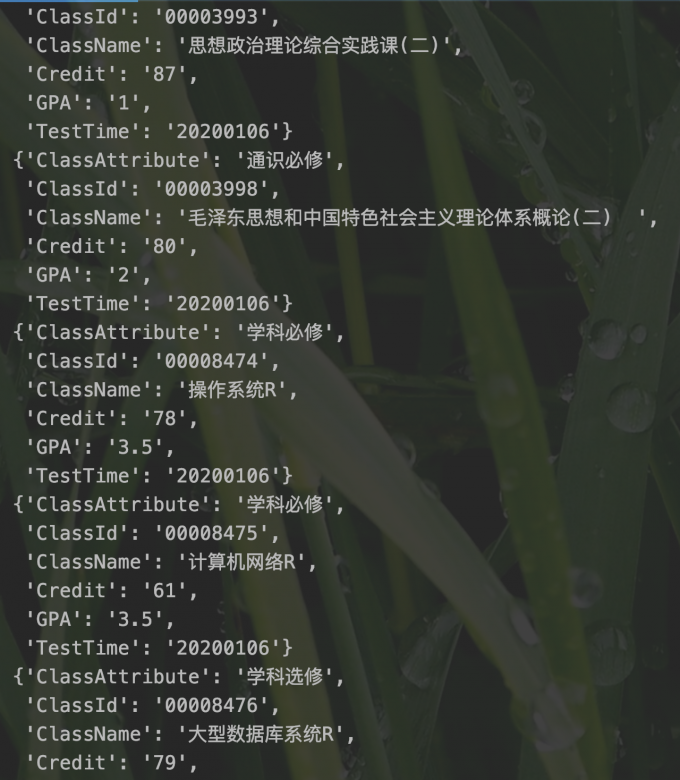
本篇博客分享就到这里结束了,如果你在通过本篇博客实际操作时出现问题,或者你需要这份爬虫的源代码,请通过QQ,或者邮件联系我